
pytorch环境配置及使用nanodet进行模型训练和识别
环境配置
这部分内容需要用nvidia显卡,如果只使用CPU识别,那么不需要在识别的电脑上配置,但是训练的电脑建议安装如下内容
CUDA安装
查看显卡驱动支持的最高CUDA版本
在命令行输入
1 | nvidia-smi |
即可显示支持的最高CUDA版本,例如我的为11.7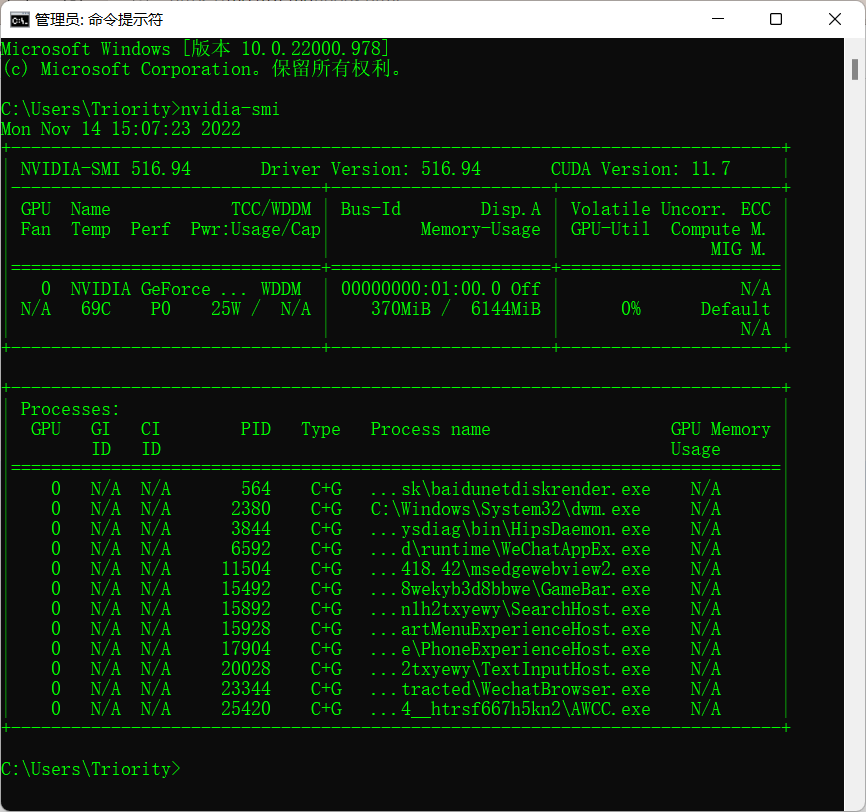
安装对应版本CUDA
官网链接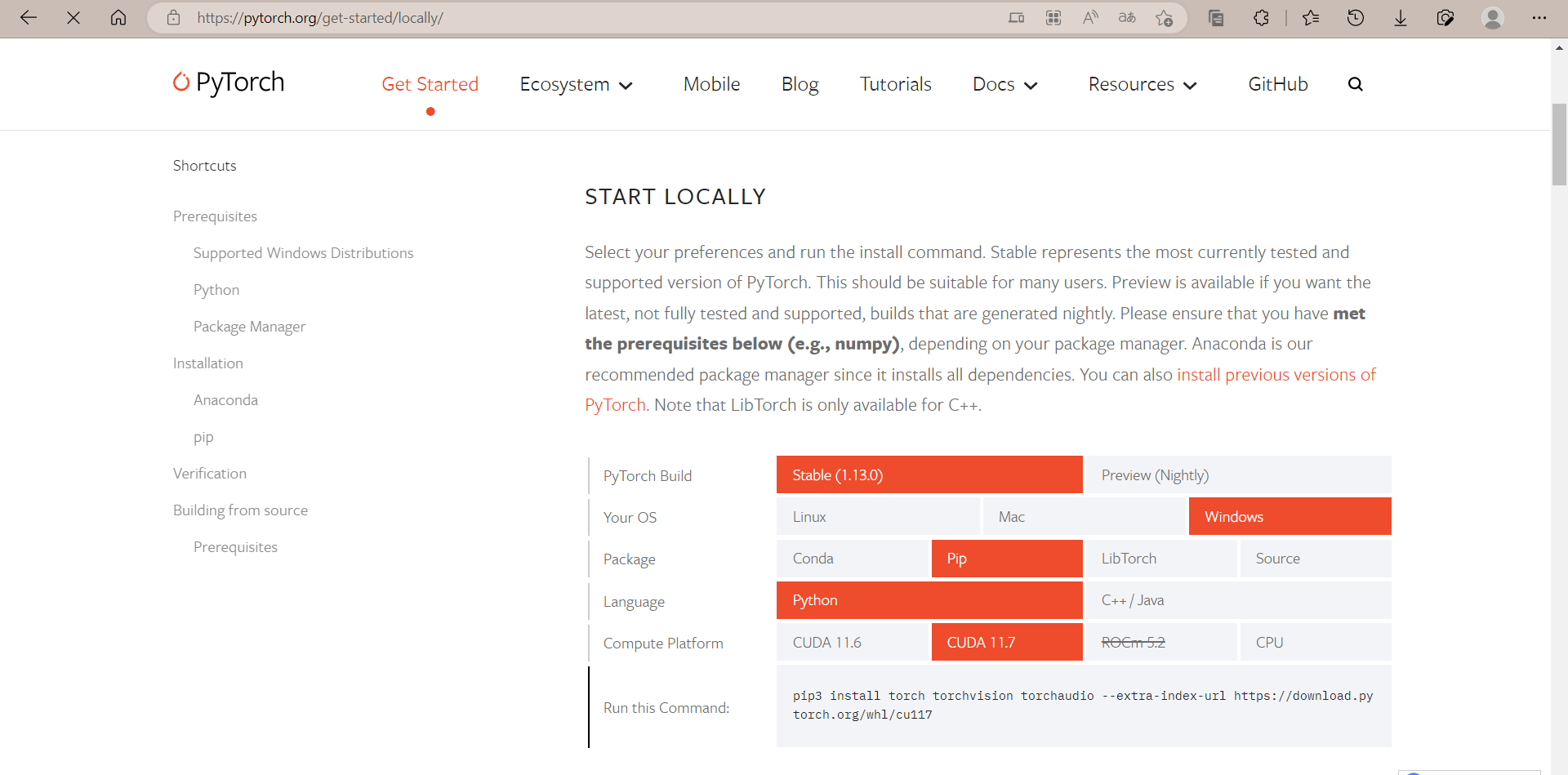
由于我不打算使用conda,因此选择pip的安装命令
选好之后复制官网下方提供的命令安装
我选择安装到python路径下,因此命令为:
1 | python -m pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117 |
其中,务必注意torch和torchvision版本对应,对应关系在这里:链接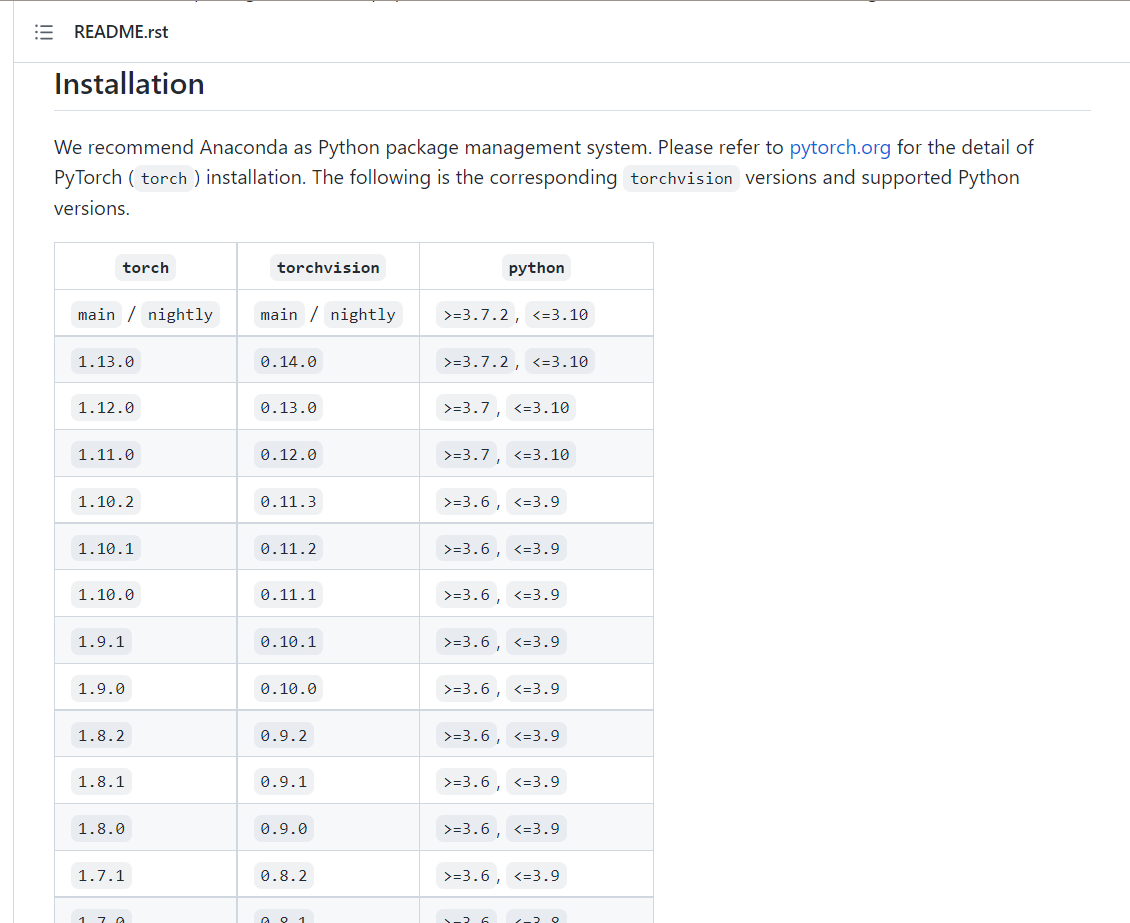
检查版本是否正确
在python中输入如下命令
1 | import torch |
如果都不报错,说明安装成功了,且torch和torchvision的版本也已经是对应的,如下: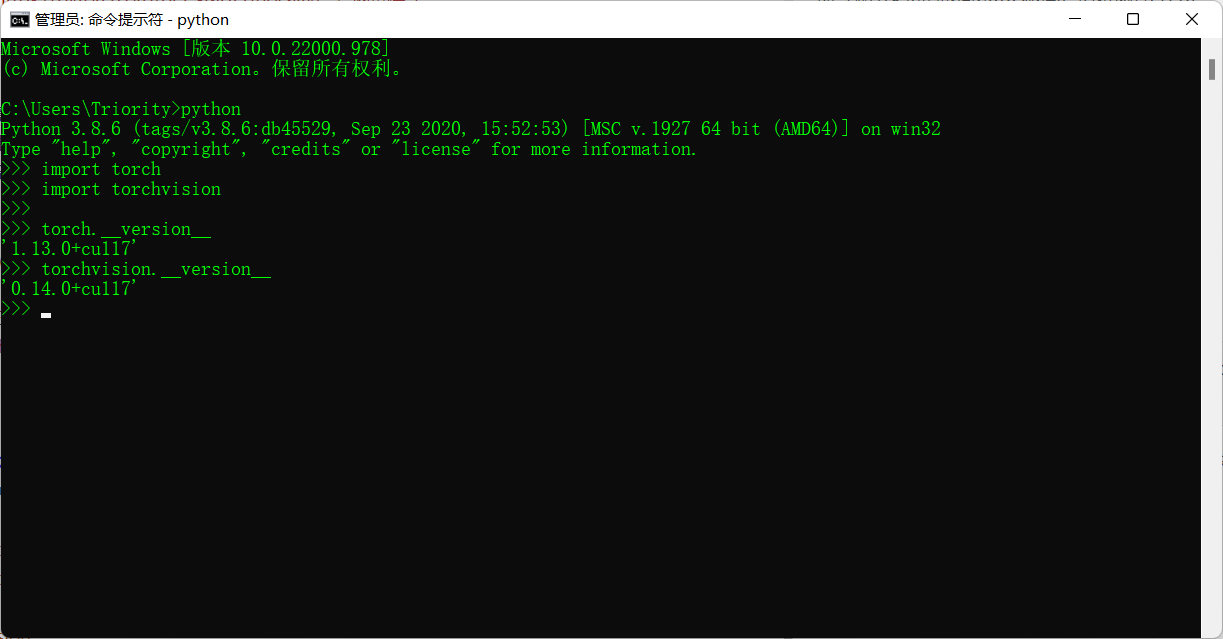
注意如果显示+CPU要卸载已安装库再重新安装
至此环境配置结束
使用nanodet提供的模型进行识别
由于我们用于识别的设备没有使用Nvidia的GPU,需要使用CPU进行识别,所以在这里使用nanodet一个使用CPU的裁剪版本
github链接
下载直接能使用,如果想使用原版nanodet:github链接
使用以下命令识别:
1 | # 图片文件 |
模型训练
数据集准备
首先使用识别用的摄像头拍摄数据集,一共需要几千张左右,可以使用我的自动标注工具生成数据集,那么需要几张识别目标的照片。
数据集标注
使用精灵标注助手进行标注,并导出为voc格式,然后使用如下工具,将voc格式数据集转换为coco格式,即可开始训练。
使用自己的电脑训练
首先修改配置文件,位于config/xxx.yml。
使用自己的模型识别
查看识别结果
外部调用识别结果
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Triority's blog!
评论