
C++学习笔记
主要内容
这篇文章是c++的学习笔记,仅作为我自己的备忘录使用,不包含我已经非常熟悉的内容,所以不适合入门看哦,最好有其他语言基础,当然我猜这玩意也没人看()
所有示例程序都是我自己重新写的简化举例可放心参考。
开发环境
windows下开发:VS studio
目前最新版本是2022,直接下载安装就能用,一切都已经准备好了
其他情况
一些开源开发者朋友们得知我要学一遍c++,非常热情的想要教会我,并且建议我用vscode连接wsl在ubuntu虚拟机内使用clang/msvc开发
基本语法
数据类型长度和范围
c++标准没用固定值的规定,但是有最小标准:
short至少16位(-32,768 - 32,767)int至少于short一样长long至少32位(-2,147,483,648 - 2,147,483,647),且至少于int一样长long long至少64位(-9,223,372,036,854,775,808 - 9,223,372,036,854,775,807),且至少于long一样长(有的系统不支持)
可以通过#include <climits>获取具体范围:
1 |
|
在我的64位windwos系统上结果为:
1 | int is 4 bytes, maximum value: 2147483647 |
输入输出函数
1 |
|
指针相关操作
1 |
|
简单IO
1 |
|
函数应用
内联函数
函数前加inline,编译器将函数代码替换函数调用,减少跳转导致的时间消耗
1 |
|
函数引用变量
使用引用变量作为函数参数,函数将使用原始数据而不是其副本,可用于函数处理大型结构或进行类的设计
1 |
|
此外需要注意,引用变量必须在创建时初始化,而且无法修改关联的变量。
使用结构引用参数只需在声明结构参数时使用引用运算符&即可。例如如下结构定义,函数原型应该这样编写,从而在函数中将指向该结构的引用作为参数:
1 | struct STRUCT{ |
参数重载
可以通过函数重载来设计一系列函数,他们名称相同,完成相同的操作,但是使用不同的参数列表(他们的返回值类型也可以不一样)。
函数模板
可以使用泛型来定义函数,避免了对函数多次几乎相同的编写
1 |
|
多文件编程
头文件
头文件应该包含以下内容:
- 函数原型
- 使用
#define或const定义的符号常量 - 结构声明
- 类声明
- 模板声明
- 内联函数
在包含头文件时,应使用a.h而不是<a.h>,后者编译器会在存储标准头文件的位置查找,而前者先在当前工作目录查找,如果没用找到再去标准位置。
为了避免包含同一个头文件多次(可能包含了另一个包含某个头文件的头文件),可以使用
1 |
存储持续性
- 自动存储:函数中定义将在函数结束后释放。
- 静态存储:在函数外定义的变量和用关键字
static定义的变量。在整个程序运行过程中存在。- 链接性为外部,可在其他文件访问,必须在代码块外声明。在一个文件中定义,其他文件使用
extern关键字声明。 - 链接性为内部,只能在当前文件访问,必须在代码块外声明并使用
static限定符 - 无链接性,只能在当前函数或代码块内访问,必须在代码块内声明并使用
static限定符
- 链接性为外部,可在其他文件访问,必须在代码块外声明。在一个文件中定义,其他文件使用
- 线程存储:使用关键字
thread_local声明,其生命周期和其所属线程一样长 - 动态存储:使用
new关键字分配,一直存在直到使用delete将其释放或程序结束。也被称为自由存储(free store)或堆(heap)
说明符和限定符
存储说明符:
- auto(c++11中不再是说明符)
- register
- static
- extern
- thread_local(c++11新增的)
- mutable
限定符:
- const
- volatile(避免编译器进行将数据复制到寄存器的优化,因为硬件等可能对其进行修改,例如串口信息)
- mutable(用于指出即使结构或类为const,其某个成员也可以进行修改)
1 | struct data{ |
名称空间
两个名称空间的相同名称将不会导致冲突。下面的代码使用新的关键字namespace创建了一个新的名称空间:
1 | namespace Triority{ |
名称空间可以是全局的也可以位于其他名称空间中,但是不能在代码块中。默认情况下其链接性为外部的(除非引用了常量)
标记一下,这一段我没写完,我要先去写cmake
多文件编译
简要介绍和安装
1 | 完成C++项目的执行过程, 主要是分为四步: 预处理、编译、汇编、链接。g++命令确实可以对一个C++项目通过上面四步转成可执行文件,但在中大型项目里面,这样还是太复杂。 于是乎就有了MakeFile。 |
安装cmake并查看版本:
1 | sudo apt-get install cmake |
目录组织
- 项目根目录下建立
build文件夹并建立CMakeLists.txt文件(和.cpp和.h在一起,这里只是最简单的演示文件)1
2
3
4
5
6
7cmake_minimum_required(VERSION 3.28)
# set the project name
project(main)
# add the executable
add_executable(main 1.cpp main.cpp) - build文件夹内使用cmake生成makefile
1
cmake ../.
- 编译项目
1
make
- 执行程序
1
./main
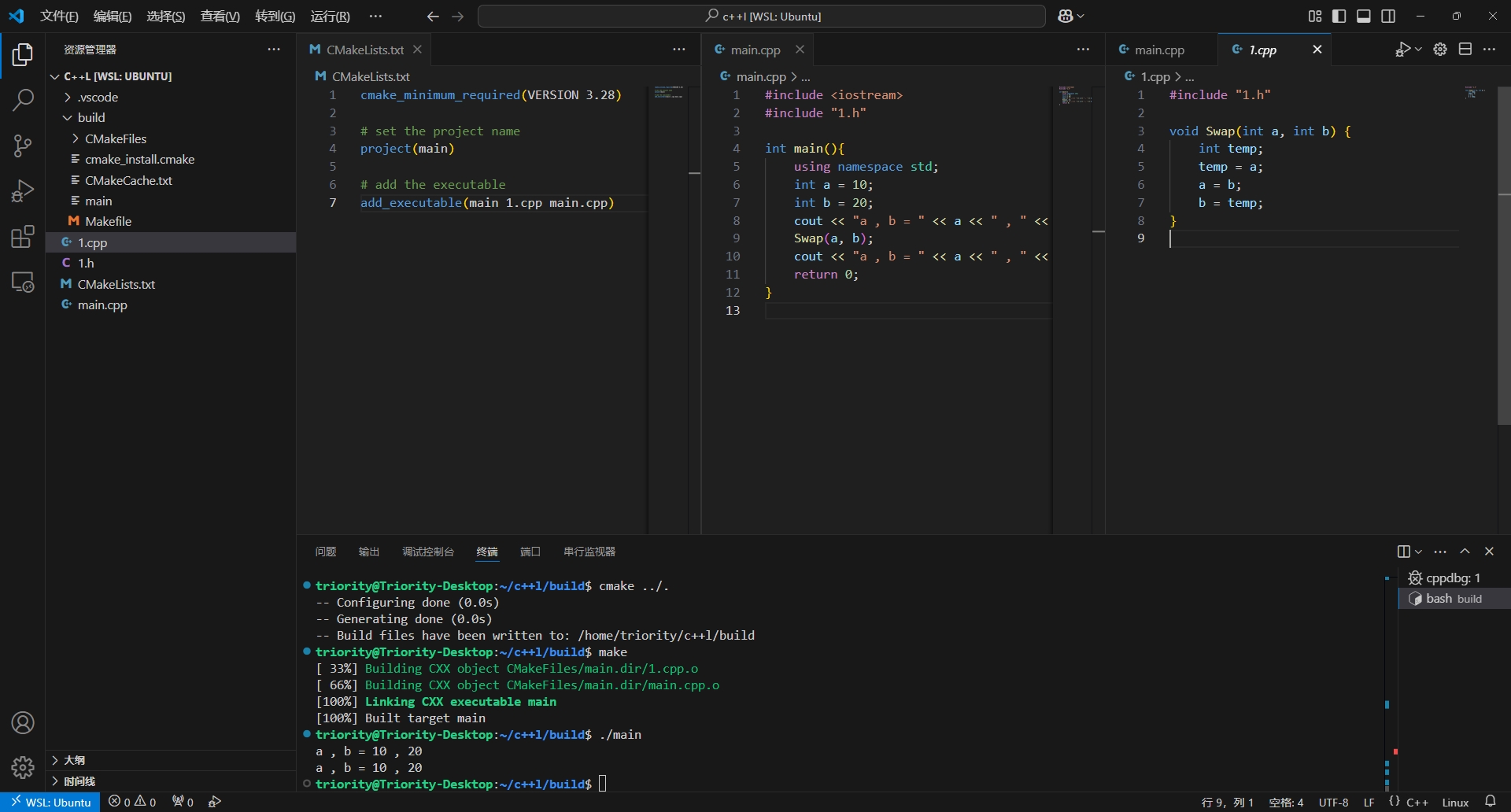
CMakeLists.txt
这里面的大部分命令都是固定语法,相当于我们只需要指定一些参数即可。 先整理上面几个命令,如果有其他命令需要用到,可以去官网查看具体使用(当然这个页面我觉得不会有人愿意看)
- cmake_minimum_required命令
cmake_minimum_required(VERSION major[.minor[.patch[.tweak]]][FATAL_ERROR])- 用于指定需要的CMake 的最低版本
- 示例:
cmake_minimum_required(VERSION 3.28)
- project命令
project( [languageName1 languageName2 … ] )- 用于指定项目的名称,一般和项目的文件名称对应
- 示例:
project(main)
- add_executable命令
add_executable( [WIN32] [MACOSX_BUNDLE][EXCLUDE_FROM_ALL] source1 source2 … sourceN)- 用于指定从一组源文件 source1 source2 … sourceN 编译出一个可执行文件且命名为name
- 示例:
add_executable(main 1.cpp main.cpp)
- include_directories命令
include_directories([AFTER|BEFORE] [SYSTEM] dir1 dir2 …)- 用于设定目录,这些设定的目录将被编译器用来查找 include 文件
vscode自动生成CMakeLists.txt
利用vscode中的cmaketools插件,可以自动生成cmakelist文件,例如需要include两个头文件生成就是这样:
1 | cmake_minimum_required(VERSION 3.5.0) |
在vscode安装cmake,CMake Tools,Makefile Tools三个插件,Ctrl+shift+p调出VSCode的指令面板,输入cmake,找到cmake:quick start,按照提示填写一个项目的名称,选择C++orC,选择构建库或者可执行文件,我这里只需要一个可执行文件,然后就会自动帮你生成一个CMakeLists
OOP:面向对象
类的定义和使用
a_class.h:
1 |
|
a_class.cpp:
1 |
|
main.cpp
1 |
|
如果要创建同一个类的多个对象,可以这样:
1 | Stock stocks[4]; |
如果使用构造函数则必须这样:
1 | Stock stocks[2] = { |
this指针
在 C++ 中,this指针是一个特殊的指针,它指向当前对象的实例。每一个对象都能通过this指针来访问自己的地址。可以在类的成员函数中使用,可以用来指向调用对象。
当一个对象的成员函数被调用时,编译器会隐式地传递该对象的地址作为 this 指针。
通过使用 this 指针,我们可以在成员函数中访问当前对象的成员变量,即使它们与函数参数或局部变量同名,这样可以避免命名冲突,并确保我们访问的是正确的变量
1 |
|
运算符重载
假设有一个Time类包含hours和minutes变量,求和的函数方法大概是这样time.h
1 | Time Time::Sum(const Time & t) const; |
time.cpp
1 | Time Time::Sum(const Time & t) const{ |
如果要使用加法运算符进行这个操作,只需要把Sum()的名称改为operator+()即可time.h
1 | Time operator+(const Time & t) const; |
time.cpp
1 | Time operator+(const Time & t) const{ |
此后计算时间总和就可以直接用+了
1 | time_total = time_1 + time_2; |
重载的使用有一些限制:
- 重载后必须至少有一个操作数是用户定义的类型,避免用户为标准类型重载,比如重载
-符号为求和 - 不能修改运算符优先级
- 重载不能违反原来的句法规则,比如将求模
%重载成只用一个操作数 - 不能创建新的运算符
- 一些不能重载的运算符:
sizeof等(懒得全写一遍了,这玩意估计八百年用不到一次)
友元
类对象的公有类发布方法是访问对象私有部分的唯一途径,但是这种限制有时候过于严格,因此提供了友元的概念,包括友元函数,友元类,友元成员函数。通过让函数成为类的友元可以赋予函数与类的成员函数相同的访问权限
在刚才的例子中可以实现时间的加法,那如果是乘法呢?由于运算符左侧是操作数,我们只能A = B * double而不能A = double * B,因为这个double不是对象。另一种解决方式就是使用友元
创建友元函数只要将其原型放在类声明中,并在前面加上friend关键字
1 | friend Time operator*(double m, const Time & t); |
显然这个函数在类声明中调用但是不是成员函数,但是拥有成员函数一样的访问权限
因为他不是成员函数,所以编写定义时不要使用Time::限定符,也不要使用关键字friend,应该这样:
1 | Time operator*(double m, const Time & t){ |
有了这些声明和定义之后,就可以使用这一语句了:
1 | Time_A = 2.75 * Time_B |
类的自动转换和强制类型转换
c++会自动转换兼容的类型,比如int a = 3.5;会只保留整数部分,不兼容的类型不会自动转换,但是也许可以强制类型转换int * p = (int *) 10;,因为p和(int *)都是指针,虽然这样的转换大概率毫无意义
对于类,当构造函数只接受一个参数时(或者其他参数有默认值),可以编写这样的代码:
1 | AClass(int a); |
如果需要避免意外的这种转换,可以在声明构造函数时使用关键字explicit,从而关闭隐式转换,但仍然允许显式转换:
1 | AClass aclass; |
转换函数可以反过来将类对象转换为一个值,这是一种用户定义的强制类型转换。要创建一个转换函数要注意,转换函数必须是类方法,不能指定返回类型,而且不能有参数。
1 | //转换为double类型的函数的原型,添加到类的声明中 |
然后在类定义中加入转换的方法(int返回double+0.5可以巧妙地四舍五入而不是丢弃小数部分)
1 | AClass::operator int() const{ |
这样调用时候便可以直接使用
1 | int a_int = aclass; |
类和动态内存分配
使用new初始化对象的指针成员时应该注意一些事情:
- 在构造函数中使用
new初始化之后,应该在析构函数中使用delete,且必须互相兼容new对应delete且new[]对应于delete[] - 如果要进行对象的复制,应定义一个复制构造函数,进行实际内容的复制,而非指针。例如
b.str是通过new创建的,类似a.str = b.str这样的直接复制只会复制地址,导致两个成员实际上指向同一份内容,并在当其中一个执行delete时导致数据损坏 - 也应该定义一个赋值运算符,通过深度复制将一个对象复制给另一个对象。具体来说,应该首先检查自我赋值的情况,释放成员指针以前指向的内存,复制数据而不是地址,返回一个指向调用对象的引用
这部分内容可能比较难懂,需要一些举例才能完全理解,但是我现在又懒得在这补充一大堆代码作为举例,因此这件事交给未来的自己吧。在此之前可以直接阅读原书的P356
类的继承
假设已经有了下面这个类(由前面的例子删减而来)1.h:
1 |
|
1.cpp:
1 |
|
我现在想要让这个类新增一个id成员,但是不想改动已有的代码(甚至可能没有源代码),那么可以直接派生出一个类:2.h:
1 |
|
2.cpp:
1 |
|
派生类需要自己的构造函数,也可以添加额外的数据成员和成员函数
但是注意不能直接访问基类的私有成员而必须通过基类方法进行访问,也就是说,private只能这个类自己访问,protected允许自己和派生类访问,public允许全部访问
派生类继承了所有的基类方法,但下列情况除外:基类的构造函数、析构函数和拷贝构造函数,基类的重载运算符,基类的友元函数。
多态继承
友元类
异常
1 |
|
使用try捕获异常,然后在catch()中对异常进行处理。(异常是新增的内容,一些老式编译器可能不支持)
1 | triority@Triority-Desktop:~/c++l/build$ /home/triority/c++l/build/main |
这一部分原来书上的代码catch (char* str)运行会报错terminate called after throwing an instance of 'char const*',这里是我改正且简化的版本。
原因是应该捕获const异常catch (const char const* strException),参考链接中还讨论了更加规范的错误处理方法和其他”style note: This tutorial smells, maybe you should find another source.”😨😨😨
想让catch块能够处理try块抛出的任何类型的异常,则必须在异常声明的括号内使用省略号...:
1 | try{ |
或者可以连续使用catch来分别处理多种异常:
1 | try{ |
通常引发异常的函数会传递一个对象,从而可以使用不同的异常类型来区分不同函数在不同情况下引发的异常。对象也可以携带可以确定异常原因的信息。C++提供了一系列标准的异常,定义在<exception>中,我们可以在程序中使用这些标准的异常,或者通过继承和重载exception类来定义新的异常
1 |
|
常用的类和模板:string类,智能指针,STL标准模板库
string
智能指针
使用new分配内存时别忘了要delete释放内存,但是别忘了这件事总是不可靠的。如果指针是一个对象就可以在过期时调用析构函数释放内存该有多好,这就是智能指针对象。
在C++11及之后的版本中,最常见的智能指针类型包括std::unique_ptr、std::shared_ptr和std::weak_ptr。
std::unique_ptr提供了独占所有权的语义,确保同一时间内只有一个智能指针指向特定的资源。在std::unique_ptr的生命周期结束时,它会自动释放所拥有的资源,无需程序员手动干预。std::shared_ptr实现了共享所有权模型,允许多个智能指针共同拥有对同一资源的引用。这种模型通过引用计数来实现,每当一个新的std::shared_ptr被创建并指向同一资源时,引用计数会增加;当std::shared_ptr被销毁时,引用计数减少。只有当引用计数降至零时,资源才会被释放。std::shared_ptr的使用也带来了循环引用的问题,这时std::weak_ptr提供了一种不控制对象生命周期的智能指针,它指向由std::shared_ptr管理的对象,但不增加引用计数。这允许程序员访问资源,同时避免循环引用导致的内存泄漏。
1 |
|
1 | triority@Triority-Desktop:~/c++l/build$ /home/triority/c++l/build/main |
STL标准模板库
C++ 标准模板库(Standard Template Library,STL)是一套功能强大的 C++ 模板类和函数的集合,它提供了一系列通用的、可复用的算法和数据结构。
STL 的设计基于泛型编程,这意味着使用模板可以编写出独立于任何特定数据类型的代码。
C++ 标准模板库的核心包括以下重要组件组件:
- 容器(Containers):容器是 STL 中最基本的组件之一,提供了各种数据结构,包括向量(vector)、链表(list)、队列(queue)、栈(stack)、集合(set)、映射(map)等。这些容器具有不同的特性和用途,可以根据实际需求选择合适的容器。
- 算法(Algorithms):STL 提供了大量的算法,用于对容器中的元素进行各种操作,包括排序、搜索、复制、移动、变换等。这些算法在使用时不需要关心容器的具体类型,只需要指定要操作的范围即可。
- 迭代器(iterators):迭代器用于遍历容器中的元素,允许以统一的方式访问容器中的元素,而不用关心容器的内部实现细节。STL 提供了多种类型的迭代器,包括随机访问迭代器、双向迭代器、前向迭代器和输入输出迭代器等。
- 函数对象(Function Objects):函数对象是可以像函数一样调用的对象,可以用于算法中的各种操作。STL 提供了多种函数对象,包括一元函数对象、二元函数对象、谓词等,可以满足不同的需求。
- 适配器(Adapters):适配器用于将一种容器或迭代器适配成另一种容器或迭代器,以满足特定的需求。STL 提供了多种适配器,包括栈适配器(stack adapter)、队列适配器(queue adapter)和优先队列适配器(priority queue adapter)等。
容器矢量vector
1 |
|
基于范围的循环和迭代器
这段内容作为一些补充,考虑到前面没有提到循环这些语法
基于范围的for循环就是为了用于STL而设计的,上面的写法for (int element : myVector){};就是遍历整个容器的内容,方便一点可以使用auto语法for (auto x : myVector) do_something(x);,使用引用参数也可以在遍历的同时修改元素内容for (auto & x : myVector) do_something(x);
STL规定了5种迭代器:
- 输入迭代器(Input Iterator):只能进行单次读取操作,不能进行写入操作。
- 输出迭代器(Output Iterator):只能进行单次写入操作,不能进行读取操作。
- 正向迭代器(Forward Iterator):可以进行读取和写入操作,并且可以向前移动。
- 双向迭代器(Bidirectional Iterator):除了可以进行正向迭代器的所有操作外,还可以向后移动。
- 随机访问迭代器(Random Access Iterator):除了可以进行双向迭代器的所有操作外,还可以进行随机访问,例如通过下标访问元素。
不同容器的迭代器的功能也不同:
| 容器 | 迭代器功能 |
|---|---|
| vector | 随机访问 |
| deque | 随机访问 |
| list | 双向 |
| set / multiset | 双向 |
| map / multimap | 双向 |
| stack | 不支持迭代器 |
| queue | 不支持迭代器 |
| priority_queue | 不支持迭代器 |
关联容器
关联容器存储的元素,是由一个个“键值对”(key, value)组成。通过键,往往能很快的检索到对应的值。
关联容器可以快速查找、读取或者删除所存储的元素,同时该类型的容器插入元素的效率比序列容器高。
STL提供了4种关联容器:
set:关键字即值,即只保存关键字的容器。set类似一个集合,用来存储同类型的元素multiset:关键字可重复出现的setmap:元素是一些键值对:关键字起到索引的作用,值则表示与索引相关联的数据,数据的存放是有序的multimap:关键字可以重复出现的map
C++ 11 还新增了 4 种哈希容器,即
unordered_map、unordered_multimap以及unordered_set、unordered_multiset。严格来说,它们也属于关联式容器。哈希容器底层采用的是哈希表。
这里以map为例简单介绍部分用法:
1 |
|
1 | triority@Triority-Desktop:~/c++l/build$ /home/triority/c++l/build/main |
书上内容的结束
原书最后两章节继续介绍了c++的IO操作和c++11新内容总结,这部分内容我认为完全没有必要单独写出来,内容又多又杂但是没有难度,用的时候上网查便是。
如果我的这篇文章接着写下去我认为应该写一些应用功能了,例如并发编程或者opencv这些标准外的库的使用,这部分内容就交给未来勤奋的自己咯! 是某个勤奋的面壁者吗?
继续深造
opencv
opencv的使用教程文章早已经写过,这里只写c++下需要进行的内容
OpenCV的功能被组织成多个模块,每个模块专注于不同的任务:
Core:提供基本数据结构和函数,如图像存储、矩阵操作、文件 I/O 等。Imgproc:图像处理功能,包括滤波、几何变换、颜色空间转换、边缘检测、形态学操作等。Highgui:图像和视频的显示、窗口管理、用户交互(如鼠标事件、滑动条)。Video:视频处理功能,包括视频捕获、背景减除、光流计算等。Calib3d:相机标定、3D 重建、姿态估计等。Features2d:特征检测与描述,包括关键点检测、特征匹配等。Objdetect:目标检测功能,如 Haar 级联检测、HOG 检测等。DNN:深度学习模型的加载和推理,支持 TensorFlow、PyTorch、Caffe 等框架。ML:机器学习算法,如 KNN、SVM、决策树等。Flann:快速近似最近邻搜索(FLANN),用于特征匹配和高维数据搜索。Photo:图像修复、去噪、HDR 成像等。Stitching:图像拼接功能,用于创建全景图。Shape:形状分析和匹配。Tracking:目标跟踪算法,如 MIL、KCF、GOTURN 等。
安装和编译配置
1 | sudo apt-get install libopencv-dev |
然后是编译配置CMakeLists.txt:
1 | cmake_minimum_required(VERSION 3.16.3) |
关于上面新增的内容做一些解释:
find_package:CMake 本身不提供任何关于搜索库的便捷方法,也不会对库本身的环境变量进行设置。它仅仅是按照优先级顺序在指定的搜索路径进行查找 Findxxx.cmake 文件和xxxConfig.cmake文件(其中xxx代表库的名字,特别注意的是有大小写之分),这两个文件大体上是没有区别的,CMake 能够找到这两个文件中的任何一个,我们都能成功使用该库。include_directories:将指定目录添加到编译器的头文件搜索路径之下,指定的目录被解释成当前源码路径的相对路径target_link_libraries:该指令的作用为将目标文件与库文件进行链接
使用
下面这个程序调用wget命令下载网站的图标(这一步是吃饱了撑的)然后显示图片
1 |
|